2023. 3. 5. 21:47ㆍ딥러닝 이론
오늘 공부한 내용은 Ch.6-1, 6-2입니다. Ch 6-1은 이론파트고 6-2는 실습 파트입니다.
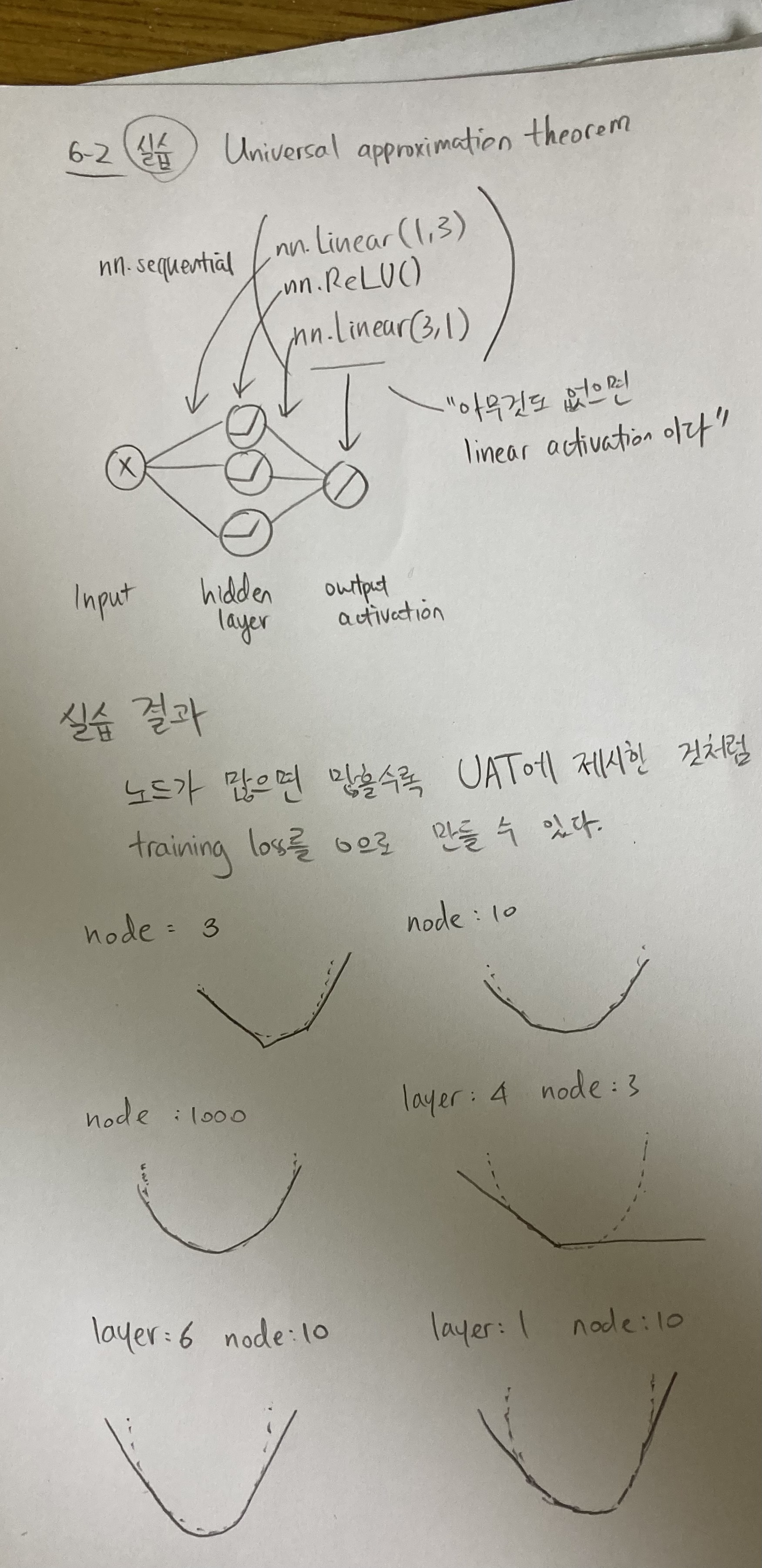
- Universal Approximation Theorem
- 왜 우리는 weights and biases구조를 쓰는가요?
- 왜 DNN을 쓰는가요?
- Input이 하나 이상이여도 Universal approximation theorem이 적용되나요?
Universal approximation theorem은 인공신경망의 한계가 없다는 이론적인 증명입니다. 이게 무슨 뜻이냐면 hidden layer가 한 층만 있어도 인공신경망은 모든 input에 대한 fitting이 가능 하다는 뜻입니다. 여기서 theoretically perfect fitting이란 function을 완벽하게 추측을 할 수 있는 것이 아니라 training loss == 0이 만들어 진다는 점을 주의 해야 합니다. Testing performance에 관에 이야기 하는게 아니라서 overfitting은 지금 토론의 대상이 아니라는 말씀이죠.
1. 왜 우리는 weights and biases구조를 쓰는가요?
우리가 weights and biases구조를 쓰는 이유는 hidden layer가 한층만 있어도 loss (MSE)가 0으로 보장할 수 있기 때문이다. weights and biases를 써도 hidden layer 없이 바로 output activation을 하면 백날 해도 training loss를 0으로 보낼 수 없고, weights and biases model조차도 안 쓴다면 layer를 늘려도 backpropagation (update parameters)를 못하기에 복잡한 function에 대해 training loss를 0으로 만들기 힘들다는 것입니다.
2. 왜 DNN을 쓰는가요?
DNN을 쓰는 이유는 사실 간단합니다. 총노드수를 줄이면서 효율을 높이는 방법입니다. Hidden layer가 더 deep해지면 node를 줄여도 performance가 더 좋아지기 때문입니다. 그래서 node를 줄임으로써 효율을 높이는 것입니다.
3. Input이 하나 이상이어도 Universal approximation theorem이 적용되나요?
네, x, y-축 인 여러 input 축이 있어도 같은 원리로 universal approximation theorem이 적용 가능합니다. 3차원 깍두기를 생각하시면 됩니다. x폭 y폭 z높이 등등 node를 거쳐 계산하면 3D깍두기가 만들어져 "tower function"라는 용어로 호칭을 합니다.

'딥러닝 이론' 카테고리의 다른 글
| Day 16: Chapter 7-3 Vanishing gradients 실습 (0) | 2023.03.07 |
|---|---|
| Day 15: Chapter 6-3, 7-1, 7-2 MLP 정리 & Vanishing gradient problem (1) | 2023.03.06 |
| Day 13: Ch.1-21 정보 이론 기초 (마지작 수학 파트) (0) | 2023.03.04 |
| Day 12: Chapter 5-4 ~ 5, MLE그리고 softmax를 이용한 다중 분류 (0) | 2023.03.03 |
| Day 11: Chapter 1-20 MAP, MLE vs. MAP비교 (0) | 2023.03.02 |