2023. 3. 7. 23:10ㆍ딥러닝 이론
오늘 공부한 내용은 Ch.7-3입니다, vanishing gradients의 실습.
어제는 Ch 7-1, 7-2를 통해 the vanishing gradient problem과 possible improvements to eliminate vanishing gradients도 배웠습니다. 오늘은 실습을 통해 어제 배운 부분에 대해 확인을 할 수 있었습니다.
1. Vanishing gradients review
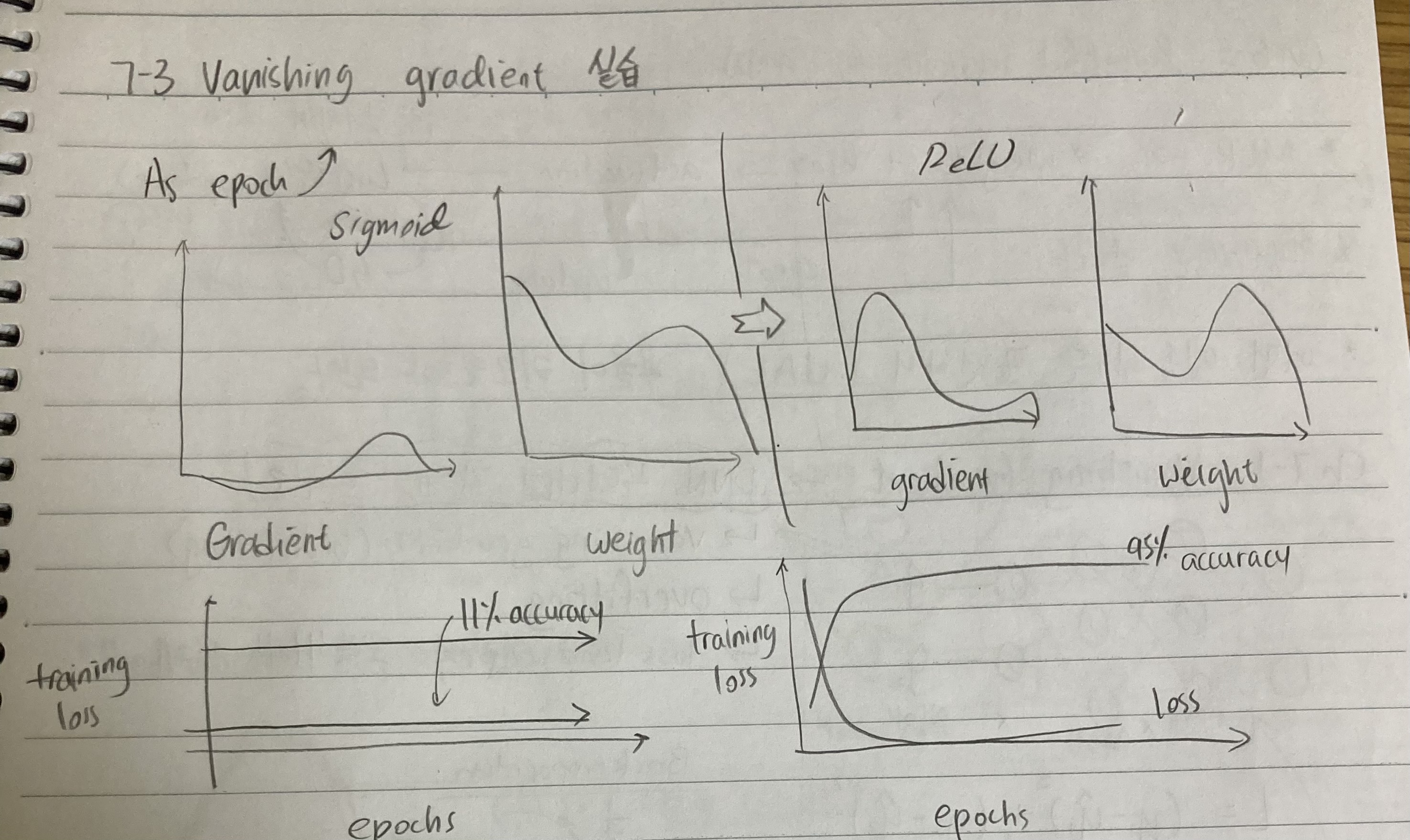
Vanishing gradients는 backpropagation때 gradient descent에서 어떻게 보면 제일 중요한 초기 weights and biases까지 영향력이 없다는 문제가 있는데요... 이는 작은 gradients를 많이 많이 multiply 하기 때문에 일어나는 문제입니다. gradients가 많이 곱해지는 것은 당연히 layer가 많기 때문이죠. 하지만 많은 layer가 꼭 필요할 때도 있죠? 이럴 때에는 다른 대처법이 필요합니다.
그러고 보니 activation을 sigmoid로 썼는데 ReLU를 쓰면 어떨까요? 네 ReLU를 쓰니 small gradients인 sigmoid function의 단점인 최대의 기울기가 0.25인 부분을 없엡니다. 하지만 ReLU 역시도 문제가 없진 않습니다. 음수나 양수만 보면 둘 다 linear이기 때문에 양수 일 때에는 vanishing gradients 문제가 해결되지만 non-linearity는 상실하게 됩니다. 음수는 더 심합니다: non-linearity도 상실하고 vanishing gradients의 문제는 여전희 고치질 못하고 있죠. 이래서 사람들은 leaky ReLU를 만듭니다. 기울기를 조금 만들어 주는 것이죠.
2. 실습결과
실습결과를 보면 node수와 layer수를 건드려서 training loss 하고 accuracy를 확인할 수 있습니다. 또한 중요한 건 sigmoid vs. ReLU activation을 비교하는 건데요. Vanishing gradients가 언제 일어나는지 실험해 볼 수 있겠죠?
왼) Sigmoid를 썼는데 weights의 변동이 있음에도 불구하고 update가 제대로 되질 않습니다 - underfitting의 증상이죠. Final test accuracy가 11.3%죠? MNIST dataset에 output class가 10종류 있으니 거의 1/10 확률로 찍고 있는 것입니다.
오) ReLU는 95.3%성능을 내고 있습니다. weights도 더 활발하게 움직이고 gradient도 많으니 학습량이 많다고도 할 수 있겠네요!
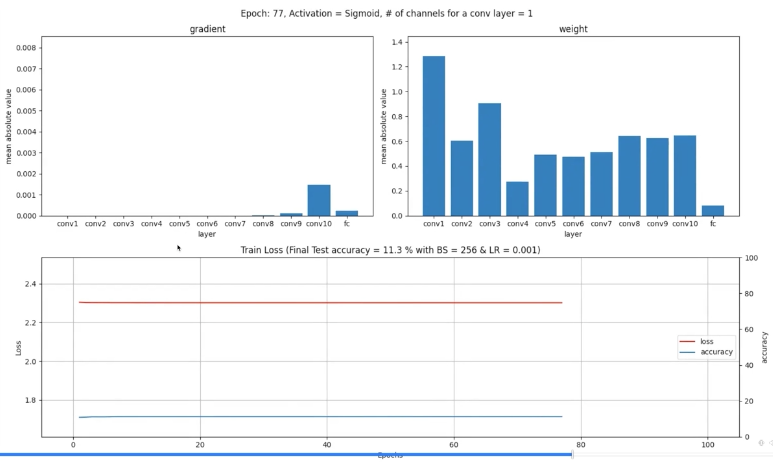
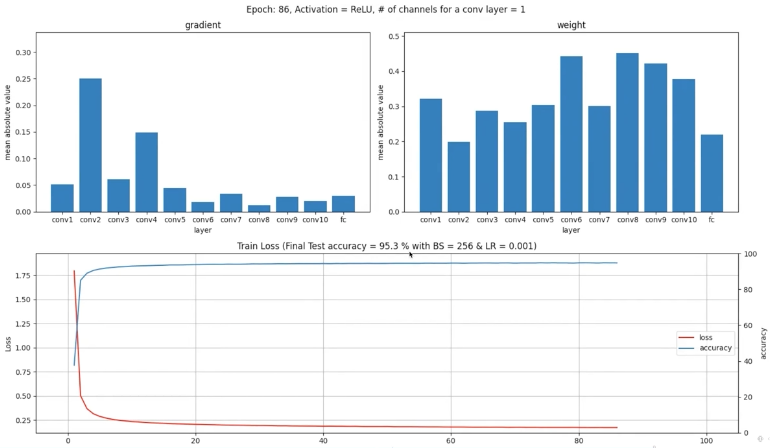
실습결과... ReLU가 sigmoid를 압승하네요
'딥러닝 이론' 카테고리의 다른 글
| Day 18: 7-5 BN 실습 & 7-6 Loss landscapes problem (0) | 2023.03.09 |
|---|---|
| Day 17: Chapter 7-4 Batch normalization (0) | 2023.03.08 |
| Day 15: Chapter 6-3, 7-1, 7-2 MLP 정리 & Vanishing gradient problem (1) | 2023.03.06 |
| Day 14: Chapter 6-1, 6-2 Universal Approximation Theorem (0) | 2023.03.05 |
| Day 13: Ch.1-21 정보 이론 기초 (마지작 수학 파트) (0) | 2023.03.04 |