2023. 2. 24. 21:01ㆍ딥러닝 이론
강의 내용이 점점 어려워져서 영상을 많이 못 봤네요. 오늘의 주제는 "MLP, 행렬과 벡터로 나타내기 & 왜 non-linear activation 중요할까?"입니다.
1. MLP
MLP가 뭔가요? MLP는 multilayer perceptron입니다. 전에 공부한 perceptron (가끔 single layer perceptron)은 단순한 인공 신경망입니다. 여기서 단순하다고 말한 이유는 layer가 1겹이라 그렇다. 0 또는 1을 출력해 binary classification에 쓰인다. 구조는 input -> final activation layer -> output이다.
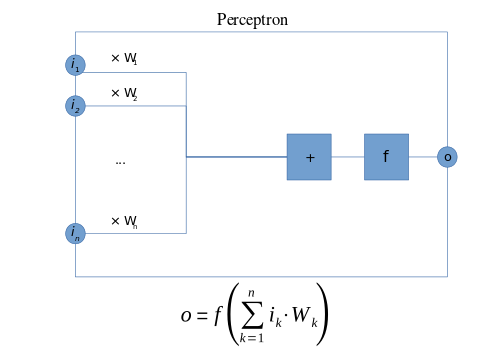
Multilayer perceptron은 hidden layer가 2이상이다. Input layer -> hidden layers -> final activation layer -> output. Multilayer perceptron은 hidden layer가 많으니까 사실상 아주 복잡한 곡선을 만들어 낼 수도 있다. 반면 single layer perceptron은 linear 한 decision boundary만 만들 수 있어 직선으로 구분이 가능하지 않은 문제에는 적절한 답을 줄 수 없는 문제가 있다.
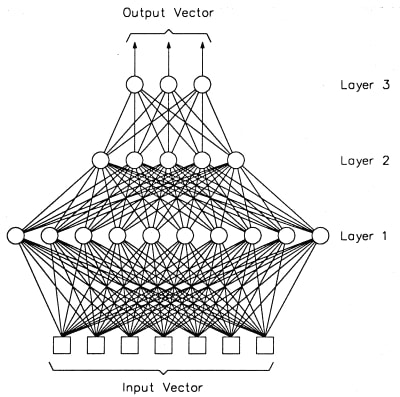
하지만 그렇다고 해서 multilayered perceptron도 무지막하게 layer를 많니 쓴다고 해서 효과가 좋은 것은 아니다. 엥?? 그럼 MLP하고 SLP의 차이는? 사실 대부분 경우에는 MLP가 났지만 MLP에 linear activation을 쓴다면 방금 말한 아무 효과가 없거나 역효과 날 수 있다는 것을 명심하기 바랍니다. 그럼 non-linear activation을 꼭 써야 하는 이유를 알아보겠습니다.
2. 왜 non-linear activation이 중요할까?
Perceptron에는 linear activation function을 쓸수 있으나 MLP에 linear activation을 사용하면 없고 parameter수만 늘어져서 오히려 결과를 더 떨어뜨릴 수 있다. 이를 이해하기 위해선 밑에 첨부한 노트를 참고 바랍니다.
왼쪽 사진에는 linear activation function을 썼을때 어떤 수학적 의미가 있는지 보여줍니다. Layer 1과 layer2둘 다 linear activation을 쓰면 ax + b과 같은 형태인 xW1W2 + W2 b1 + b2이다. 왜 같은 형태인지 잘 안보이시나요? 그러면 xW + b vs. xW1W2 + (W2 b1 + b2)로 생각해도 좋습니다. 결국 linear activation을 2 layer로 겹쳤지만 결과는 그냥 linear 한번 쓰나 별 다를 게 없습니다.
중간 사진을 보면 2 -> 3 -> 2가 사실은 2 -> 2형식과 사실상 같은 구조를 갖고 있고, parameter만 많아져 training효율이 떨어질 수도 있다는 것을 알 수 있습니다.
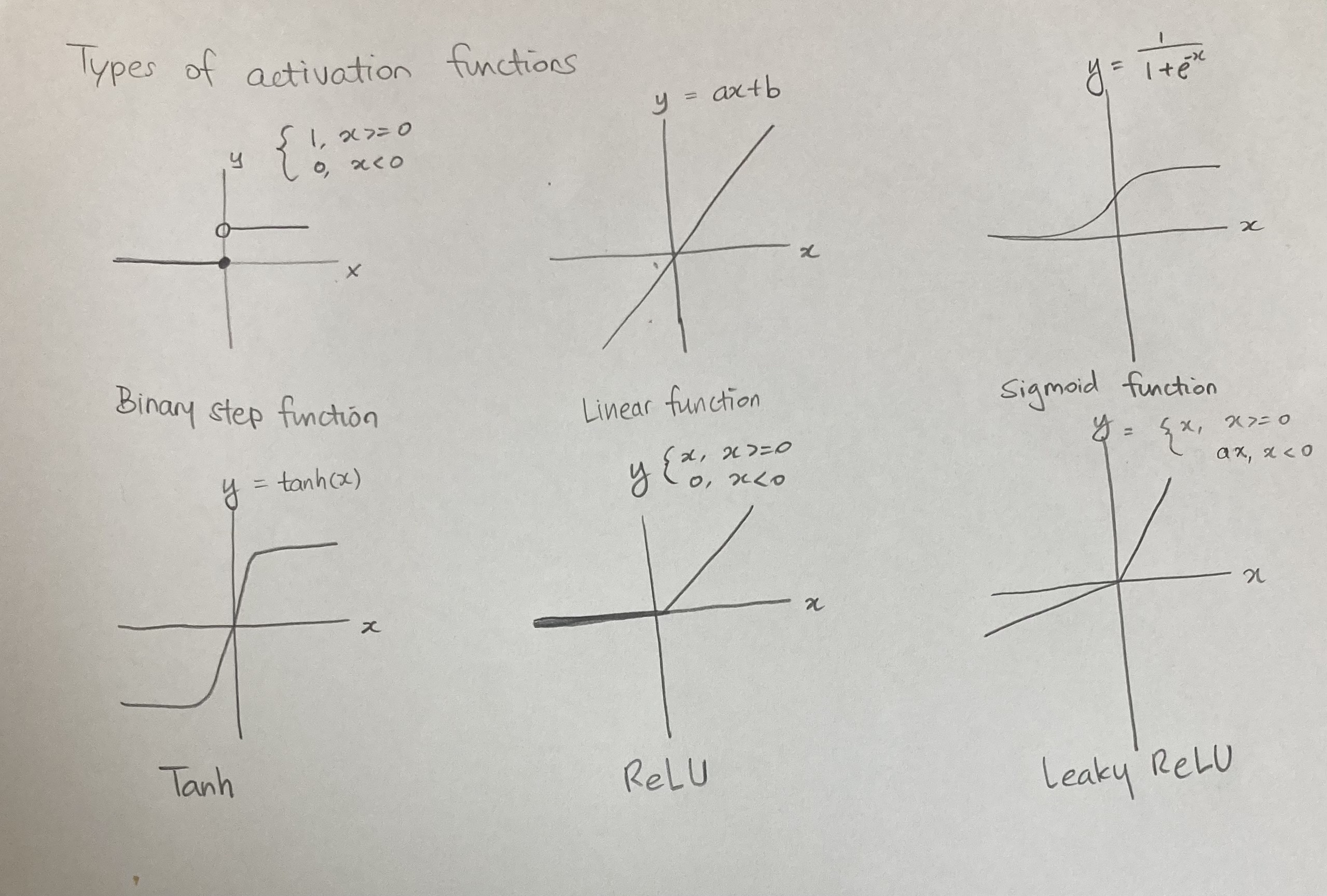
오른쪽 사진은 많이 쓰이는 여러가지의 activation function들입니다.


'딥러닝 이론' 카테고리의 다른 글
| Day 7: Chapter 1 gradient, 벡터를 벡터로 미분하는 법 (0) | 2023.02.26 |
|---|---|
| Day 6: Chapter 4-2 Backpropagation, 깊은 인공신경망의 학습 (0) | 2023.02.25 |
| Day 4: 왜 우리는 인공 신경망을 공부해야 하는가? Part 2 (0) | 2023.02.23 |
| Day 3: Chapter 3. 왜 우리는 인공 신경망을 공부해야 하는가? (Part I) (0) | 2023.02.22 |
| Day 2: 왜 현재 AI가 가장 핫할까? (0) | 2023.02.21 |