2023. 2. 23. 23:43ㆍ딥러닝 이론
오늘의 공부: Ch 3-6에서 3-10까지
- mini-batch SGD
- Moment
- RMSProp
- Adam (adaptive moment estimation)
- Training, validation, test data
- K-fold cross validation
어제에 이어서 챕터 내용을 진행하겠습니다: 이번에는 어제 공부한 SGD를 더욱 완화해 줄 것입니다. Mini-batch를 통해 낱개의 error에서 mini-batch-size만큼의 hyperparameter를 사용해 SGD가 tuning가능하게 만들면서 GD의 문제점을 어느 정도 고쳐주고. 어떻게 SGD의 방향이 '휙휙'튀는 현상을 더 '스무드'하게 만들어 주는 moment 또는 momentum, 그리고 마지막으로 RMSProp를 통해 그 방향도 평준화를 해주는 작업을 배우게 될 것이다. 이 모든 거를 합친 optimizer가 Adam이고 이 말고도 많은 optimer들이 존재한다. 다시 리마인드를 하자면 optimizer는 loss function의 implementation이라고 볼 수 있을 것 같습니다. Loss function은 포괄적인 단어고 Optimizer 구체적인 구현방식을 요구하죠 - 알고리즘으로 따지면 priority queue를 구현한 방법으로는 heap가 있는 것처럼요.
결론적으로 오늘은 optimzer인 moment, rmsprop, adam 등을 알게 될 것입니다.

TIL...
1. Mini-batch SGD:
Andrew Ng의 Coursera강에서 mini-batch를 구현한 기억은 있으나 왜 mini-batch가 필요했는지는 잘 몰랐다는 거를 오늘 알게 되었네요. 저는 mini-batch를 쓰면 training도중에 서버전원이 끊겨도 training 한 weights가 autosave 되는 용도로 생각했지만... 어림도 없네요!
전에 GD는 모든 error를 계산해 계산이 느려지는 문제가 있는 반면, SGD는 낱개의 error를 loss로 삼아서 방향이 올라갔다 내려갔다 난리가 아니었죠. Mini-batch SGD는 이 error를 낱개인 1개 대신 batch_size만큼으로 정합니다. 그래서 batch_size = 3이면 '주머니'에서 3개의 error를 꺼내 loss를 계산하고 방향을 3개의 error를 고려한 방향이 되니 단연히 낱개보다는 튀는 현상이 덜 할 것입니다.
여기서 주의를 해야 할 것은 batch_size가 너무 커지면 learning속도가 확 줄는 현상이 있어 결국에는 mini-batch를 쓰는 장점이 없어지는 포인트가 있습니다. 그래서 batch_size를 2배 늘릴 때마다 learning rate도 2배로 늘려줘야 한다. 이것을 linear scaling rule이라 부른다.
2. Moment + RMSProp = Adam
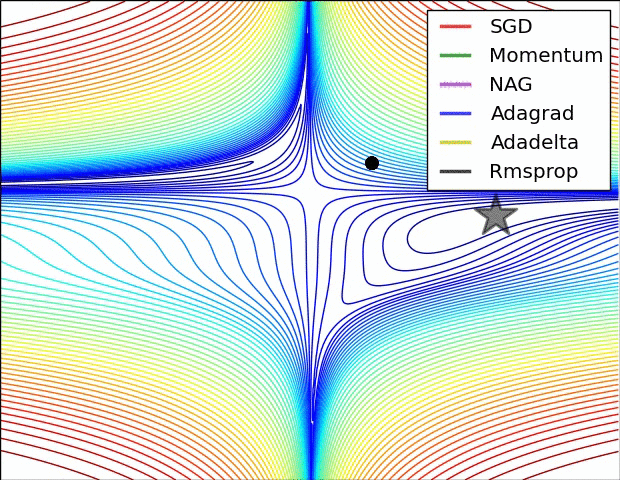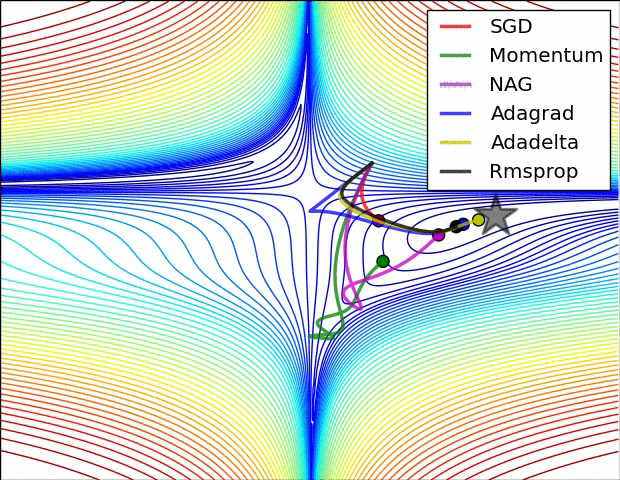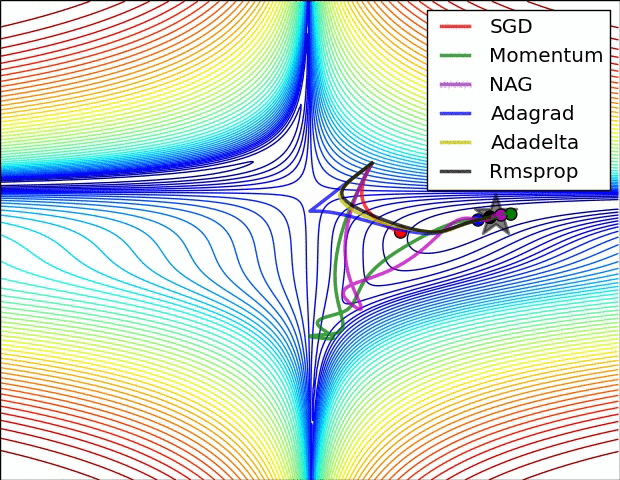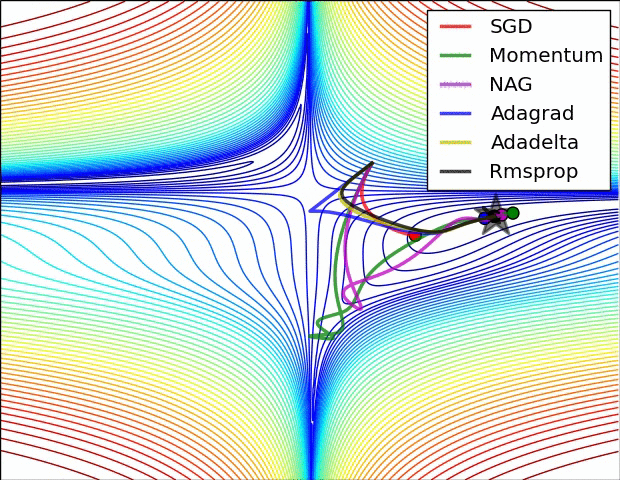
인트로에 첨부한 사진을 보면 optimizer들이 SGD에서 두 색깔로 나눠어 지는데요: 스텝방향(하늘색)하고 스텝사이즈(핑크)입니다. Moment는 스텝방향을 진정해 줍니다. 물론 방금 말한 mini-batch도 그런 역할을 하지만 효과는 batch_size에 따라 진정이 안될 수도 있습니다. 그래서 moment는 아예 loss에 관성을 붙이자는 철학을 가지고 있습니다. 이번 loss의 계산에 저번 loss의 1/2 정도의 영향을 주면 되지 않을까? 맞습니다, 실제로 수학적 수식으로 표현할 땐 복잡하지만 실질적인 의미와 계산은 비슷합니다.
그리고 ML에서 흔히 불리는 "saddle problem"이 있으나 momentum은 그 문제를 잘 극복해 낸다. 전 단계의 loss를 아예 사용 안 하고 mini-batch도 사용 안 한 SGD는 unstable equilibrium에서 그냥 멈춥니다. 하지만 momentum은 그걸 극복해 더 loss가 낮은 곳으로 향하죠.
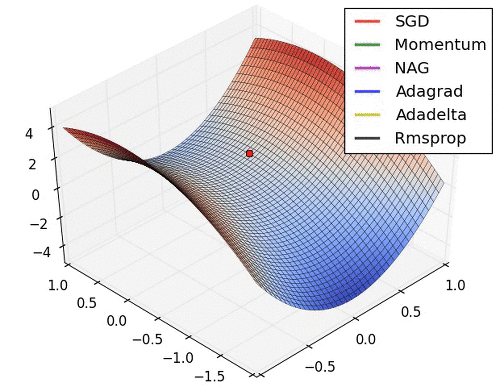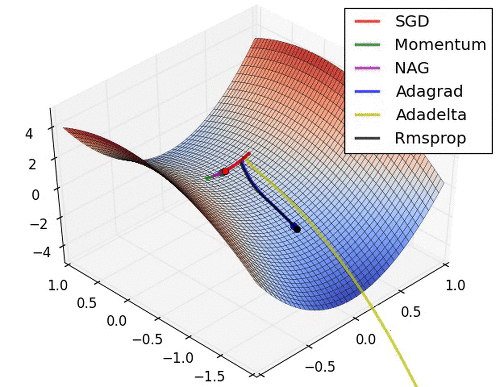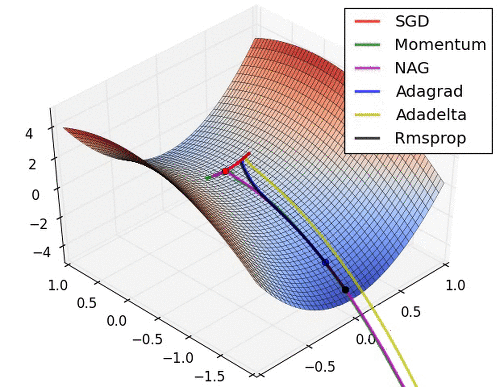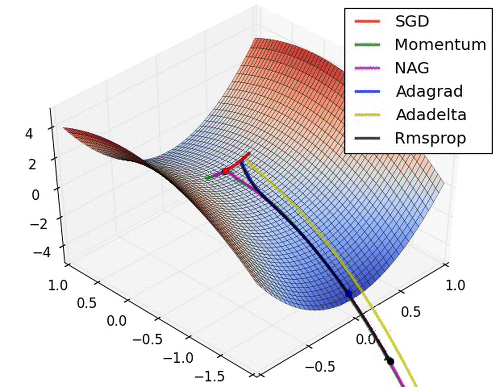
이제 스텝방향은 어느 정도 잡았으니 스텝크기도 조정해야 되는데요. 스텝크기는 RMSProp을 상용한다. 솔직히 수식은 잘 이해가 안 가지만 직관은 그냥 vector인 loss의 숫자를 다듬에 줘서 평준화를 하는 것이다. 효과는 경사가 가파른 곳을 천천히 가고 가파르지 않은 곳은 빨리 가는 습성을 가져 이것도 saddle문제를 해결하는 데에 도움이 된다.
Adam (adaptive moment estimation)은 moment과 RMSProp을 합친 것이다. GD와 SGD의 약점들을 한방에 공략해서 아주 많이 쓰인다고 한다.
3. Training, validation, test dataset, k-fold cross validation
Training data는 연습 문제다. 학생이 교과서를 보고 연습문제를 푸는 것이다. Validation은 모의고사다. validation data는 training data에서 소수를 뽑아야 한다. Validation data로 hyperparameter tuning을 하게 되니 그의 중요성은 그만큼 중요하다. Validation data에 bias가 있으면 모든 튜닝이 헛된 수고가 될 수 있으니 k-fold cross validation기법을 사용한다.
예를 들어 동물 사진을 분류하는 DNN을 만들고 있다. 나는 뭣도 모르고 Validation data를 마지막 50장의 사진으로 정한다. 하지만 사진 데이터는 썩여 있지 않고 사진목록이 고양이 1~100, 강아지 101~200, 코끼리 201~300이다. 그러면 validation set은 251~300이 되니 실제로 validation과정(모의고사)을 할 때 코끼리 사진만 채점하게 되어 hyperparameter는 코끼리 분류만 위한 것이 되는 대참사가 일어날 수 있으니 사진을 사전에 썩거나 그냥 여러 번의 validation 하게끔 만들면 이런 위험을 예방할 수 있다.


'딥러닝 이론' 카테고리의 다른 글
| Day 6: Chapter 4-2 Backpropagation, 깊은 인공신경망의 학습 (0) | 2023.02.25 |
|---|---|
| Day 5: Chapter 4-1 MLP, 행렬과 벡터로 나타내기 & 왜 non-linear activation 중요할까? (0) | 2023.02.24 |
| Day 3: Chapter 3. 왜 우리는 인공 신경망을 공부해야 하는가? (Part I) (0) | 2023.02.22 |
| Day 2: 왜 현재 AI가 가장 핫할까? (0) | 2023.02.21 |
| Day 1: 딥러닝을 위한 기초 수학 (0) | 2023.02.20 |