2023. 3. 17. 22:45ㆍ딥러닝 이론
오늘 공부한 내용은 Ch.8-6, 8-7입니다:
- VGGNet, 그리고 VGGNet의 실습
이제 CNN을 배웠으니 CNN의 implementation인 VGGNet에 대해 알아봅시다. VGGNet은 2014년에 Oxford의 VGG (Visual Geometry Group)에서 만들었습니다. 10년이 지난 논문이지만 아직도 image recognition분야에서는 많이 사용되는 아주 중요하고 클래식한 모델이라고 할 수 있겠습니다.
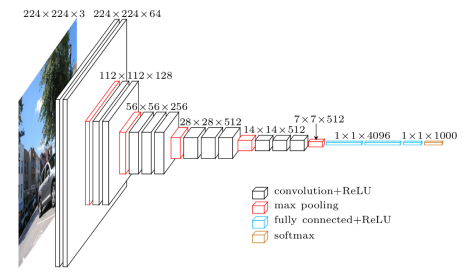
VGGNet의 architecture는 이렇습니다: 저번에 배운 filter를 이용해 convolution연산을 하고 stacking을 하여 feature map을 얻어 max pooling으로 이어나가는 모델입니다. 끝에 가면 다시 MLP에서 공부한 FC4096 layer로 최종적으로 softmax에 도달해 예측을 만드는 단계에 옵니다.
복습을 하자면:
- filter를 통한 convolution연산을 하면 weights and biases에서 패턴 맞추기를 실행한다, 패턴이 잘 맞는 경우에는 숫자값이 높아진다.
- conv를 하다보니 image size가 점점 작아지는걸 볼 수 있다. 하지만 feature map를 점점 많이 쌓다보니 image size는 작아지지만 feature map의 개수는 점점 많아져 두툼해집니다.
- convolution + ReLU사이 사이에는 Max pooling이 진행되고 있습니다. max pooling은 local에서 가장큰 값을 고르면서 그 local안에서의 가장 키포인트만 저장합니다.
- 결국에는 1 by 1인 FC로 된다. 이부분은 우리의 95%의 parameter들이 있어 아주 calculation heavy한 부분이라 할 수 있다.
- softmax에서는 결과를 예측한다 -> input image가 1000개의 가능한 entity에 대한 가능성을 전부 다 percentage로 점수를 매긴다.
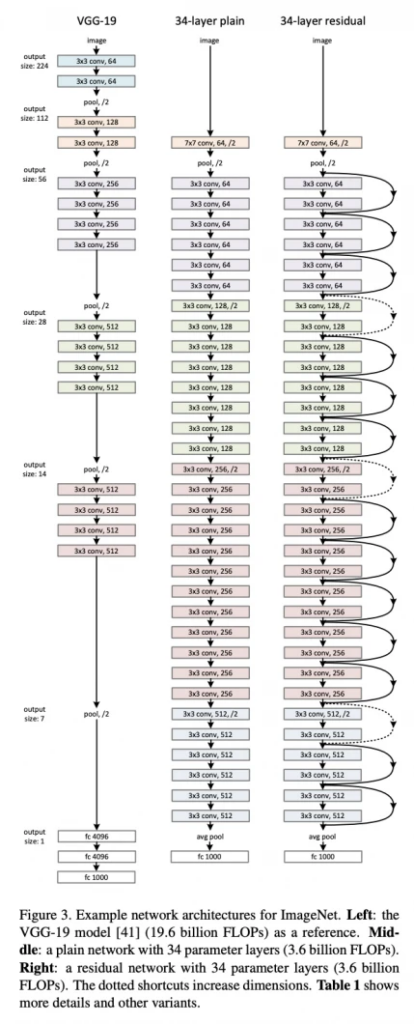
VGGNet이후에도 연구가 계속 진행이 되었는데 연구자들은 depth가 깊을수록 더더욱 performance가 좋다는 것을 볼 수 있어 depth를 늘리려 했습니다..

하지만 layer를 늘리면 또 gradient vanishing problem이 있어 2015녀에 skip connection을 사용한 ResNet은 50~150 layer까지 가능함을 보여주었고, 더더욱 좋은 성능을 보여주었습니다.
코드를 보면 자기가 인터넷에서 찾은 이미지를 업로드해서 테스트를 할 수 있습니다. 이미지 size를 맞추기 위해 cropping이 일어나는데요, 그 동물의 얼굴이 중간에 있지 않으면 다른 부위만 cropping할 수도 있으니 주의! 결과는 top 5로 줍니다. 이정도 performance만 보여도 진짜 사람보다는 잘한다고 생각이 되네요.



'딥러닝 이론' 카테고리의 다른 글
| Day 28: 9-1, 9-2 RNN, RNN backpropagation 그리고 구조적 한계 (0) | 2023.03.19 |
|---|---|
| Day 27: 8-8 Beautiful Insights for CNN (CNN 마무리) (0) | 2023.03.19 |
| Day 25: 8-4, 8-5 Padding, stride, pooling and CNN feature map (0) | 2023.03.16 |
| Day 24: 8-2, 8-3 CNN filter에 대한 추가 설명 (4) | 2023.03.15 |
| Day 23: 8-1, 이미지 딥러닝, 왜 CNN이 답인가? (0) | 2023.03.14 |