Day 20: Chapter 7-8, Overfitting 개념과 Data augmentation
2023. 3. 11. 23:50ㆍ딥러닝 이론
오늘 공부한 내용은 Ch.7-8입니다:
- Overfitting 개념과 Data augmentation
- Dropout and dropconnection
전 파트에서 Underfitting은 많이 언급이 되었었다 - training loss가 "말이 안 될 정도"로 높을 때이다. 그러면 Overfitting에 대해서도 배워보자. Overfitting이란 반대로 training loss는 아주 낮은데 validation/testing accuracy는 낮은 training loss, 즉 높은 training accuracy에 비해 많이 낮은 상황입니다. 숙제를 잘 풀지만 시험은 망치는 스타일이라고 해야 할까요? 근데 뉘앙스는 좀 더 숙제를 다 베껴서 시험을 망치는 듯한 느낌이 이해에 더욱 도움이 될 것 같네요 ㅎㅎ.
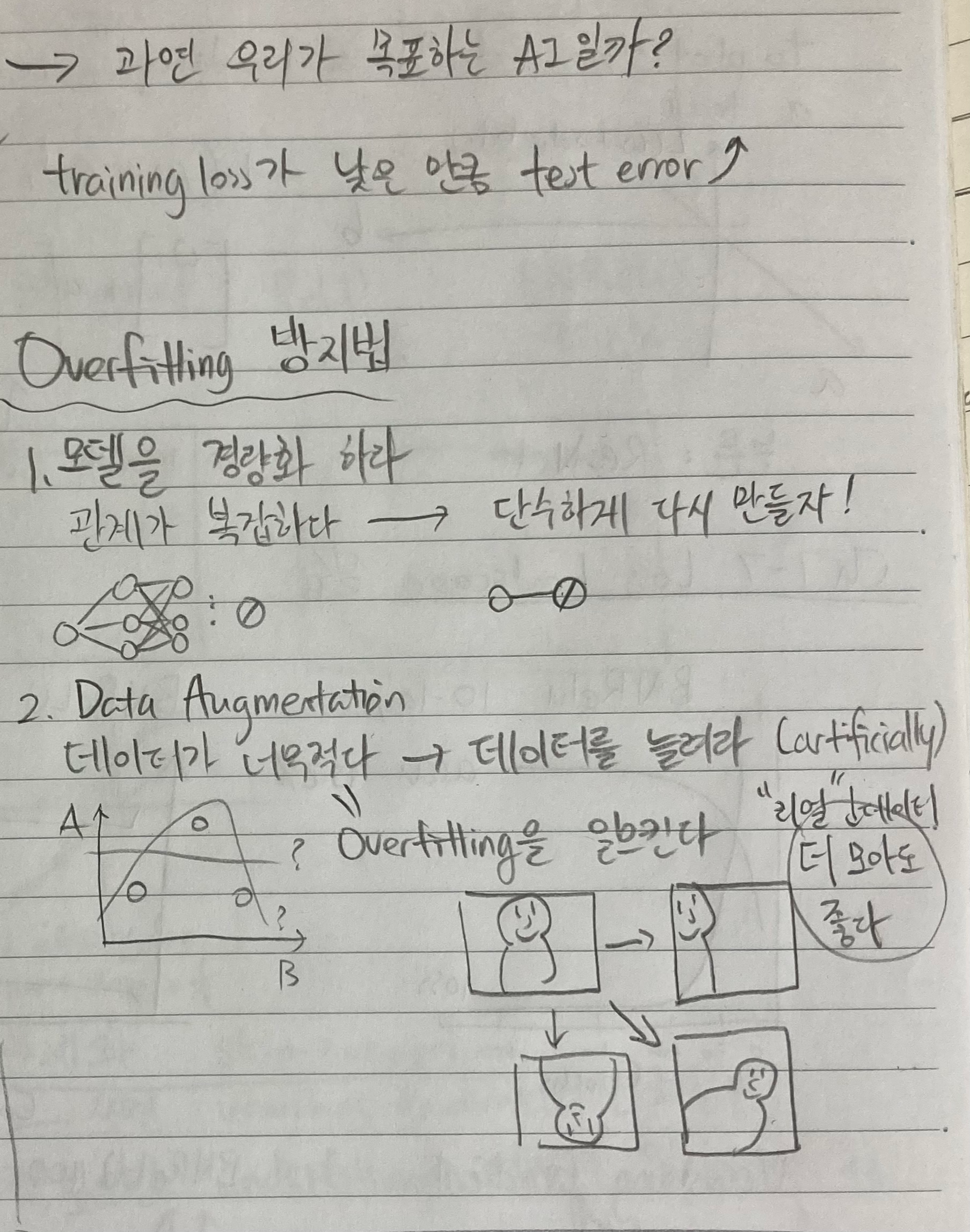
1. Overfitting방지법, 뭐뭐가 있을까?
Overfitting방지법:
- 모델 경량화
모델은 깊고 복잡하면 (many layer, many nodes) vanishing gradients처럼 알게 모르게 쌓이는 부분에서 문제가 생긴다. 그래서 overfitting이 의심이 되면 시도해볼께 모델 경량화이다. - Data augmentation
DL은 첫 수업에도 언급을 했지만 ML에 포함이 되고 "ML은 데이터 기반 알고리즘이다"라고 했었다. 하지만 DL은 ML보다 자동으로 처리를 하는 부분이 많아 데이터가 훨씬 더 많이 필요하다. 그래서 작은 양의 데이터로 어떻게 요구하는 것은 overfitting을 초래할 수 있다. 하지만 데이터마다 다르지만 구하기 비용이 많이 들거나, 많이 존재하지 않거나, 많은 인력 또는 시간이 필요한 경우에는 어쩔 수 없이 데이터를 만들어야 한다. 그래서 data augmentation이라는 기술이 쓰인다. 고양이 사진이 input일 때, 사진은 좌우로 뒤집고 색깔도 살짝 변형시키고 cropping도 해본다. 근본적으론 같은 데이터지만 재활용을 해서 양질의 데이터를 더 쉽게 구할 수 있는 좋은 기술이다. - Dropout & dropconnection
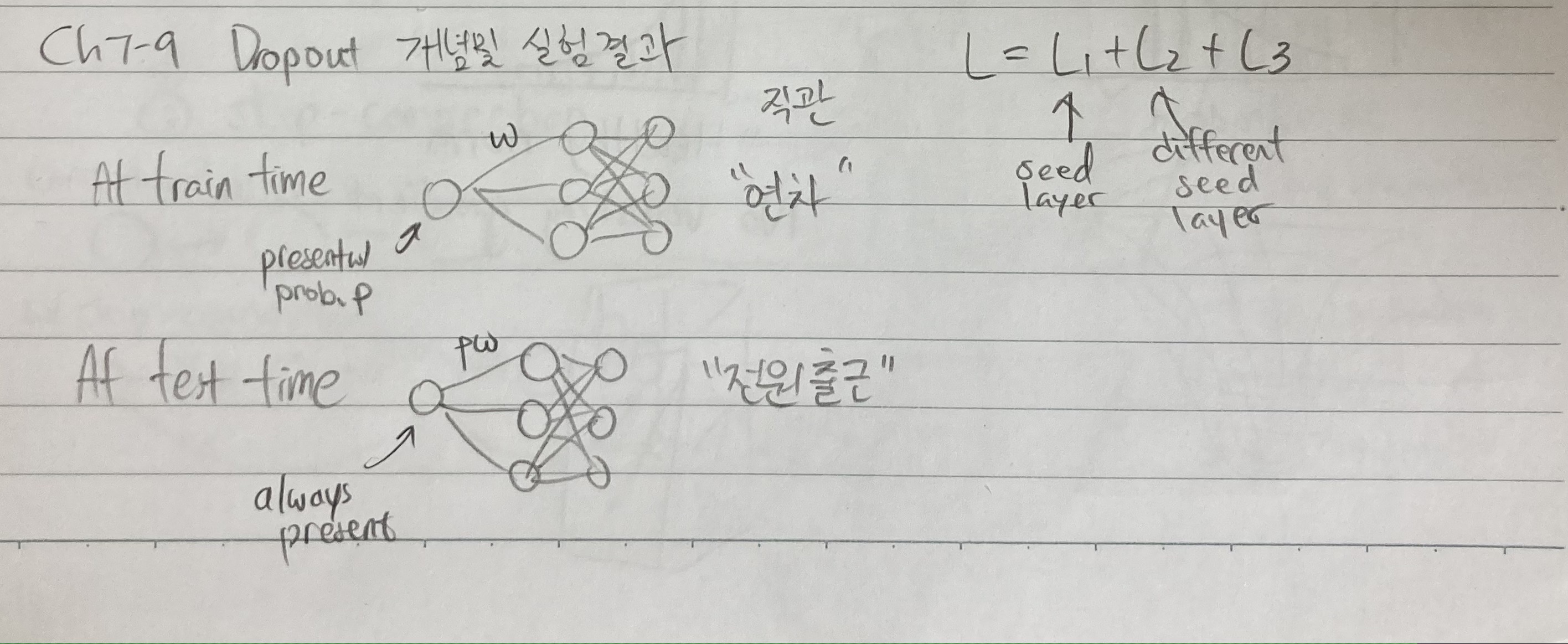
Dropout은 어떻게 보면 모델 경량화랑 느낌이 비슷하지만 조금 다르다. Hyperparameter, p는 어느 한 노드를 살리거나 없엘 확률이다. 노드가 여러 개 있을 때 사실 하나하나의 노드들이 도대체 무엇을 잘하고 있는지 확신하긴 쉽지 않다. 그래서 차라리 모든 노드들이 역할을 맡게 하는 것이 dropout이다. 노드를 랜덤으로 몇 개 없애버린다고 하자. 어느 날 회사에 출근을 했는데 사무실에 반이 연가를 썼다. 그러면 남아 있는 직원들은 원치 않게 할 일이 많아지고 중요한 건 다른 직원들을 일들을 떠맡게 된다. 이러면 노드마다 실력이 쌓인다. 여러 임무를 할 수 있으니, 한 업무만 담당하는 주임에서 팀장급으로 업그레이드된다. 자세한 내용은 다음장에 설명하겠습니다. Dropconnection은 node대신 connections, 즉 edge를 확률에 따라 없애는 technique이다.
그래서 오늘은 overfitting을 방지하는 법을 몇개 공부해 봤습니다. 내일은 dropout에 대해 더 공부해 보겠습니다. 감사합니다!!
'딥러닝 이론' 카테고리의 다른 글
| Day 22: 7-10, Regularization의 개념 및 실험 (0) | 2023.03.13 |
|---|---|
| Day 21: 7-9 Dropout, dropconnection 개념과 실습 (0) | 2023.03.12 |
| Day 19: Chapter 7-6, loss landscape 실습 (0) | 2023.03.10 |
| Day 18: 7-5 BN 실습 & 7-6 Loss landscapes problem (0) | 2023.03.09 |
| Day 17: Chapter 7-4 Batch normalization (0) | 2023.03.08 |